basic part
排序
785-QuikSort 786-Select_QuickSort
最重要的是边界的思考,和对于比较点的选择:
每次无论左边还是右边的移动找可交换点,都应该不包含等于边界点的情况,因为如果跳过,那么就会出现死循环的情况,比如132,left从1开始一直移动到2,right会保持到2,那么就会一直卡在这个循环(在选择比较点为中点的情况),对于比较点的值,就算作left和right共同的分界线点,会进行交换.
写的时候记得几个特殊情况:1332,这会让left和right都停在3,所以if判断需要涵盖left==right的情况,并且以选取right作为分隔,这是因为除法的向下取整的原因,这里不能把left作为分界(除非向上取整,模板改成p[(left + right+1) >> 1];)
select 快排只是变形,我们找第K小的数只需要去除不必要的递归,因为每次递归会缩小区间,只需要递归第K小的数所在的区间即可
787-merge_sort 788 reverse_pairs
归并排序,分治法的典型应用,需要注意的是,归并排序的时间复杂度是O(nlogn),空间复杂度是O(n),因为需要一个额外的数组来存储排序后的结果,所以在空间复杂度上不如快排,但是在稳定性上要好于快排.这里细节上比快排简单,分界点取到mid,因为向下取整的原因,要分成[left,mid],[mid+1,right]两个区间,不然12的时候是死循环。然后分成合并两个递归后保证了大小顺序的区间,最后记得复制结果到原始数组,因为递归返回后还会使用这个结果。
寻找逆序对这里是一个简单的变形,因为要找到所有的逆序对,那么就分成一小段一小段找,和找第K大的数类似,因为对于排好序的区间,那么内部不存在逆序,只能是前一半区间对后一半区间可能存在有逆序对,这样就能先分割为小区间,然后再合并的时候找逆序对(从最小的,元素数量为1的区间开始左右合并),就能找完所有的逆序对。
二分
789-number_range 790-cubic_equation
分别去找下界和上界
找下界时,mid向下取整,主要是考虑12情况(找1),这个时候mid如果是1,那么right就会一直为1,所以要向下取整,这样mid就会为0。
同样,找上界时,应该向上取整,比如12(找1),这个时候如果mid是0,那么left就会一直为0,所以要向上取整,这样mid就会为1。
本质来说,之所以死循环,是前一次的mid和后一次的mid是一样的,也就是left、right没有移动,找上界时,进行向上取整就是因为上界的<=判定是移动left到mid,因为向上取整,所以mid是不可能等于left的,所以不会出现死循环的情况。对于找下界,道理是一样的。
解三次方程,就是在范围内找mid的三次方最接近target的值,这里的mid是double类型,所以要注意精度问题,还有范围,开三次方的范围一般是-|n|到|n|,但是对于小于1的来说,它的范围应该是-1到1,然后在里面用二分法,一直找mid,直到精度满足要求。
高精度
791-high_precision_add 792-high_precision_sub
高精度加法,就是模拟手算,从低位到高位,逐位相加,然后进位 高精度减法,就是模拟手算,从低位到高位,逐位相减,然后借位,但是这里有不少细节是和加法不一样的:做减法的时候,减数和被减数有很大区别,对于结果最后carry=1需要变负数的情况,需要格外注意,需要将再做一次减法得到绝对值,然后再加上负号,并且所有情况到最后的时候都需要去除前导0。
while(index + 1 != M - 1 && long_int_r[index + 1] == '0') index++;
并且加减法里面,都需要注意输入到数组里面,高位是放在低地址的,所以后面对元素处理的时候数组索引很重要
793-high_precision_mul
它和加法是类似的,我们的加法更通用的做法是:A和B放在两个vector里面,数字的高位低位放在vector的低位到高位,然后我们执行加法操作 按位加,比如这里我们18 + 96 就是先等于 (10)(14)然后再一位位处理,从低位到高位,和手是一样的,不过计算的速度会变高(纯是因为计算操作集中了,算法没变)结果就是:114。乘法这里沿用这样的思路,但是注意,我们的产出应该就最多只有A的长度加上B的长度,因为最大的情况,比如99999,那么它比1001000小,也就是100000小,所以一定是5位以内,也就是说一定保持在两个长度之和以内,我们再来看怎么乘法的。很简单:就是把两个数我们先同样的乘加起来,和手算A的一位乘上B的每一位并且偏移A当前位的距离-1。所以我们明白,A[i] * B[j]应该对应着 C[i+j] 因为我们这里的索引都是从0开始,那么位置应该是(i+1 -1 )+ (j + 1) - 1 = i + j是c产出的索引。
794-high_precision_div
这里就是朴素的想法,基本上大数的计算我们就是回归到手算的方式来思考,做除法,那么就从高位开始,我们算第一位最高位的结果,就是最高位被除数除以除数,商是0也先放在最高位,对于他们的余数,我们会移交到下一位计算,下一位计算的时候会将上一位(高位)除的余数结果乘10,然后加上这一位本身,继续同样的做除法,后面的下一位也是统一的操作,于是我们还能进一步把第一位最高位的操作给统一,设置最开始的余数位是0,这样就统一起来了。将被除数A的所有位数都遍历走完,我们最后的余数就是结果,从高位放到低位的商就是最终的商,这样就完成了所有的计算。最后将这样的商给去除掉前置的0,就是最终的结果了。
前缀和与差分
795-prefix_sum 796-matrix_sum
从最简单前缀和入手,思路类似于二分,就是我们将问题拆解简化,想要任意区间的和,那么我们可以拆解为假设知道了任意位置其前项的和的情况下,只需要做减法,sum[right] - sum[left-1]我们就能得到结果,而这个sum就可以通过遍历一遍数组得到,遍历方法是在知道前i-1项的基础上,我们的第前i项和就是前i-1项和+第i项即可。也就是sum[i] = sum[i-1]+array[i]。这个思路很重要,我们将其扩展到二维的矩阵。 二维矩阵下,我们同样先看看,要得到一个范围的矩阵和,如果知道了每个矩阵点其与原点(0,0)构成的子矩阵的和,那么去求左上和右下两点各自组成的矩阵的时候,我们很容易得到:result = sum[rigt_down_x][right_down_y] - sum[right_down_x][lef_up_y-1] - sum[left_up_x-1][right_down_y] + sum[left_up_x-1][left_up_y-1] 于是我们的问题就能变成怎么去求矩阵每个点和原点的子矩阵和,这个同样通过遍历一次矩阵就能算到,方式也很简单:sum[i][j] = sum[i][j-1] + sum[i-1][j] - sum[i-1][j-1] + array[i][j] 整个思路里面,难的是想到把问题简化拆开,通过一次遍历产生足够的信息解答后续的query,而这一次遍历的类似递归(或者说动态规划)这种想法,在这里是比较简单的,想着用前面已知的算到新的,不断更新,注意一个细节是我们索引从1开始,并且把0处索引位置都置零,去合并边界情况,相当于给我们的矩阵/数组包围了一圈0的屏障。
797-difference 798-difference_matrix
前面一维的情况很简单,就是将前缀和逆过来,我们需要减少遍历区间,将输入的一维数组差分为离散,认为原输入为是前缀和sum数组,我们需要的是离散数组,这样对于l,r范围内+c的操作,我们只需要对l索引处的离散值+c就保证其后的前缀和都会加上c,然后再r+1处-c,将确保r+1后的前缀和在前面+c之后保持不变。同样的操作我们举一反三到二维矩阵,那么先逆运算到差分形式,这个很简单,因为我们知道从差分到前缀和的公式是: sum[i][j] = sum[i][j-1] + sum[i-1][j] - sum[i-1][j-1] + array[i][j] 我们这里逆向就是需要解出array[i][j]而已知的是sum矩阵,所以就能得到:array[i][j] = sum[i][j] - sum[i][j-1] - sum[i-1][j] + sum[i-1][j-1],这里可以看到,我们更新i,j的时候,只需要用到前面位置的内容,那么我们可以从最后元素按照先列后行的顺序一个个更新,这样更新的元素并不会参与到后续元素更新,也就不会造成结果错误,不需要多开一个数组计算。对于差分矩阵,这里的更新就会比一维数组复杂一些,主要是看下面这个图解:
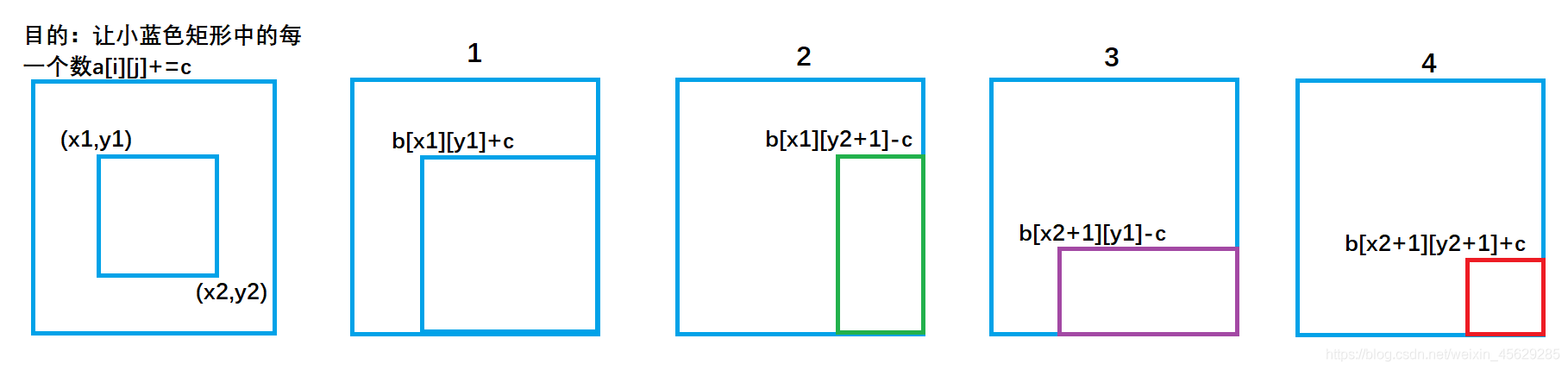 这个图解表明,我们对b[x1][y1]+c会使得后续所有元素的前缀和加c(图1中右下方蓝块),为了保证不多加,我们会同样减去一些,也就是把b[x1][y2+1]和b[x2+1][y1] -c去抵消,而重复减的地方需要再补上,也就是b[x2+1][y2+1]的地方+c,这样就保证了只有x1,y1到x2,y2的区域加了c,其他地方都没有变化,这样就完成了差分矩阵的更新操作。
这个图解表明,我们对b[x1][y1]+c会使得后续所有元素的前缀和加c(图1中右下方蓝块),为了保证不多加,我们会同样减去一些,也就是把b[x1][y2+1]和b[x2+1][y1] -c去抵消,而重复减的地方需要再补上,也就是b[x2+1][y2+1]的地方+c,这样就保证了只有x1,y1到x2,y2的区域加了c,其他地方都没有变化,这样就完成了差分矩阵的更新操作。
双指针算法
799-longest_non_repeat
要找最长连续不重复的子序列,我们选用两个指针left和right来标定区间,在这个区间里面没有重复的,并且通过设置bucket方式检查记录重复序列,当发现right走到触发重复的时候,我们这种情况的最长已经到了,需要移动left到刚好不重复的位置使得能继续重新找最长区间,首先这里会看看是否能更新最长长度,然后我们通过bucket找到重复的索引位置,移动left到该索引的下一个,这样[left,right]这个闭区间里面就没有重复的了,注意这里判断重复的时候一定是这个重复的元素(记录在bucket里的)是在当前我们的[left,right]这个最大区间中的,如果不在这个里面,那就不需要进行left移动,然后一直遍历到right走完整个序列索引,即可找到最长的不重复序列。
800-array_target_sum
关键是这里的A、B两个array是已经排序过了的,题目说明一定能找到解(其实找不到解我们这个方法仍然可行),不妨从A的最小值开始,从B的最大值开始(颠倒也可),如果它们加和的值小于目标值,那我们需要增大,就移动A数组指针,不可能移动B,移动B指针只会越来越小,移动完之后,如果加和值大于目标值,有两个选择A数组指针左移和B数组指针左移都可以减小,但是移动A数组指针左移,是回到曾经检查过的位置,A之所以右移,就是加和值太小,那么左移一定不能达到目标值(注意我们是按顺序来的,这个模拟过程是连贯的),那么只能移动B数组指针左移让他变小,而如果又遇到了加和值变小的情况,同样这时候有两种选择,移动A和B数组的指针向右都能增大加和,但是移动B指针向右,那就是曾经检查过,肯定是会过大,所以只能移动A,如果此时移动A数组指针的值仍然小了,我们继续让A的指针右移增大加和值。
所以总结起来就是我们加和值小的时候,让B数组指针向前移动,减小,加和值大的时候,让A数组指针向前移动,增大,如果你加和值小的时候移动A指针能达到target,是不可能的,因为你之前就已经访问过A,但是那个时候B要么比当前的B更大,要么就一样,可你移动了A,说明当时的加和值比target要小,那当前的值不可能是target。核心代码如下
while(b >= 0 && a <= m - 1)
{
if(A[a] + B[b] == x)
{
printf("%d %d\n", a, b);
break;
}
if(A[a] + B[b] > x) { b--; }
else { a++; }
}
2816-sub_seq
检查是否存在子串,很简单,我们需要完整遍历b数组,然后匹配到a数组当前指针指向位置就移动a数组指针,然后继续,直到a数组指针被遍历完全或者b数组指针被遍历完全,结束之后如果a遍历完了,那么就说明有,反之则无。
位运算
801-binary_ones
要找到二进制数中1的个数,这里有个巧妙的功能函数实现:lowbit,是找到一个数其为1的最低位的位置的数字对应的值,这里利用int的反码的性质,它是按位取反+1,导致第一个为1(最低端)的位置,一定是1,而其前面的位一定是0,其后面的位一定是和原来是相反的,所以将它和原来的数字做按位与,一定是只有最低为1的位是1,其余全是0,这样我们把原来的数减去这个数字,就能逐步一次次的去掉每一位的1,并且记录次数,这个方法很高效,有几个1就只会执行几次。
离散化
802-interval_sum
这个题目是先得把用户输入的所有index进行统计,我们需要建立一个映射:将按照升序排列的数轴索引,建立一个方式能根据它们的值找到他们位置对应的位置索引,相对于前缀和,我们需要根据之前用户的输入(数轴索引,加值)产生一个离散数组,这个数组就按照他们的位置索引存放对应的加和值,然后产生前缀和,然后处理query:(数轴索引左,数轴索引右),然后我们根据数轴索引知道其位置索引的范围,从而我们能够用前缀和的公式得到区间和,即是结果。这里排序和去重(去重是去掉重复的数轴索引),我们用到了STL的方法,具体是:
// sort and remove repeate in `all`
all.erase(std::unique(all.begin(), all.end()), all.end());
std::sort(all.begin(), all.end());
顺便,在不用unordered map来记录数轴索引和位置索引的情况下,我们能使用二分查找的方式更快的做到找到目标数轴索引对应的位置索引,因为我们存放数轴索引是有序的,那么简单的二分就能解决这个问题,二分注意除2之后的边界条件,这里我写了一种不会错的,对升序,先看target是否等于mid,等于直接return,然后target大于mid的时候,移动left到mid+1,反之移动right到mid-1,注意边界不能越过即可:
int find_index(int x)
{
int l = 0, r = all.size() - 1, mid;
while(l <= r && r >= 0)
{
mid = (l + r) >> 1;
if(all[mid] == x) return mid + 1;
if(all[mid] < x)
l = mid + 1;
else // if(all[mid] > x)
r = mid - 1;
}
// indicate that no find
return -1;
}
区间合并
803-interval_combine
因为区间的两头都是不固定的,那么我们应该固定一头,方便的我们固定到最左边按照left升序来排用户的区间对(left,right),在这里只需要把pair放入vector中,调用sort,默认会按照first排序然后才按照second排序,然后我们就维护一个最大区间就好了,最开始最大区间就是第一个pair的区间,如果下一个的left在区间内,那么就不会割裂,并且如果此时它的right超过了区间,就可以拓展区间了。这里考虑算法正确性,在割裂判断的时候,不可能后面有一个pair能扩大当前的区间,因为后面的left都必定在当前区间之后,这个区间已经不可能扩大了,则应当割裂,通过这种方式就能够一个个的找出最大区间(割裂的时候将区间更换为使得其割裂的pair的区间),然后计数记录就行了。